Publications
Check our book: Dive into OCR @ China Machine Press
Preliminary Research
-

Unsupervised LIDAR Point Cloud Segmentation by Finding Spatiotemporal Correspondences
Xiao Li, Pan He†, Aotian Wu, Sanjay Ranka, Anand Rangarajan
† indicates the corresponding author. To appear soon
Paper Abstract Project page Bibtex
-
Constrained Autoencoders: Incorporating Linear Equality Constraints in Lossy Data Compression
Jaemoon Lee, Anand Rangarajan, Pan He, Tania Banerjee, Sanjay Ranka
Under review for TNNLS
Paper Abstract Project page Bibtex
-
An Efficient Semi-Automated Scheme for Infrastructure LiDAR Annotation
Aotian Wu, Pan He†, Xiao Li, Ke Chen, Sanjay Ranka, Anand Rangarajan
† indicates the corresponding author
Paper Abstract Project page Bibtex
Machine Learning for IoT: Datasets, Perception, and Understanding. Workshop @ ICLR 2023
Under review for T-ITS
Most existing perception systems rely on sensory data acquired from cameras, which perform poorly in low light and adverse weather conditions. To resolve this limitation, we have witnessed advanced LiDAR sensors become popular in perception tasks in autonomous driving applications. Nevertheless, their usage in traffic monitoring systems is less ubiquitous. We identify two significant obstacles in cost-effectively and efficiently developing such a LiDAR-based traffic monitoring system: (i) public LiDAR datasets are insufficient for supporting perception tasks in infrastructure systems, and (ii) 3D annotations on LiDAR point clouds are time-consuming and expensive. To fill this gap, we present an efficient semi-automated annotation tool that automatically annotates LiDAR sequences with tracking algorithms while offering a fully annotated infrastructure LiDAR dataset -- FLORIDA (Florida LiDAR-based Object Recognition and Intelligent Data Annotation) -- which will be made publicly available. Our advanced annotation tool seamlessly integrates multi-object tracking (MOT), single-object tracking (SOT), and suitable trajectory post-processing techniques. Specifically, we introduce a human-in-the-loop schema in which annotators recursively fix and refine annotations imperfectly predicted by our tool and incrementally add them to the training dataset to obtain better SOT and MOT models. By repeating the process, we significantly increase the overall annotation speed by three to four times and obtain better qualitative annotations than a state-of-the-art annotation tool. The human annotation experiments verify the effectiveness of our annotation tool. In addition, we provide detailed statistics and object detection evaluation results for our dataset in serving as a benchmark for perception tasks at traffic intersections.
-
Expressing Linear Equality Constraints in Feedforward Neural Networks
Anand Rangarajan, Pan He, Jaemoon Lee, Tania Banerjee, Sanjay Ranka
arXiv:2211.04395
Paper Abstract Project page Bibtex
@article{rangarajan2022expressing,
title={Expressing linear equality constraints in feedforward neural networks},
author={Rangarajan, Anand and He, Pan and Lee, Jaemoon and Banerjee, Tania and Ranka, Sanjay},
journal={arXiv preprint arXiv:2211.04395},
year={2022}
},
We seek to impose linear, equality constraints in feedforward neural networks. As top layer predictors are usually nonlinear, this is a difficult task if we seek to deploy standard convex optimization methods and strong duality. To overcome this, we introduce a new saddle-point Lagrangian with auxiliary predictor variables on which constraints are imposed. Elimination of the auxiliary variables leads to a dual minimization problem on the Lagrange multipliers introduced to satisfy the linear constraints. This minimization problem is combined with the standard learning problem on the weight matrices. From this theoretical line of development, we obtain the surprising interpretation of Lagrange parameters as additional, penultimate layer hidden units with fixed weights stemming from the constraints. Consequently, standard minimization approaches can be used despite the inclusion of Lagrange parameters -- a very satisfying, albeit unexpected, discovery. Examples ranging from multi-label classification to constrained autoencoders are envisaged in the future.
Spatiotemporal Point Cloud Processing
-
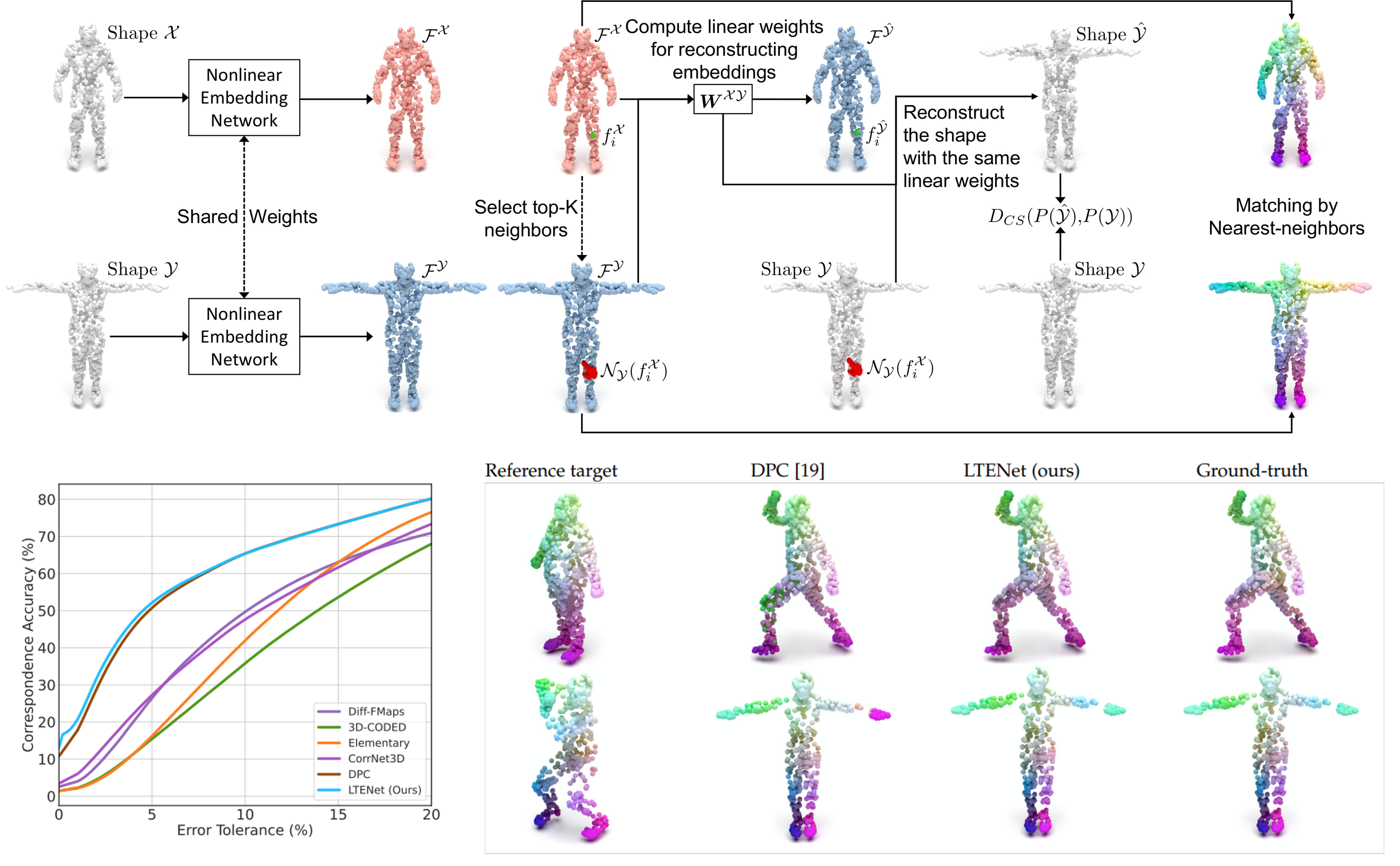
Learning Canonical Embeddings for Unsupervised Shape Correspondence with Locally Linear Transformations
Pan He, Patrick Emami, Sanjay Ranka, Anand Rangarajan
arXiv:2209.02152.
Paper Abstract Project page Bibtex
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
@article{he2022learning,
title={Learning Canonical Embeddings for Unsupervised Shape Correspondence with Locally Linear Transformations},
author={He, Pan and Emami, Patrick and Ranka, Sanjay and Rangarajan, Anand},
journal={arXiv preprint arXiv:2209.02152},
year={2022},
},
We present a new approach to unsupervised shape correspondence learning between pairs of point clouds. We make the first attempt to adapt the classical locally linear embedding algorithm (LLE)—originally designed for nonlinear dimensionality reduction—for shape correspondence. The key idea is to find dense correspondences between shapes by first obtaining high-dimensional neighborhood-preserving embeddings of low-dimensional point clouds and subsequently aligning the source and target embeddings using locally linear transformations. We demonstrate that learning the embedding using a new LLE-inspired point cloud reconstruction objective results in accurate shape correspondences. More specifically, the approach comprises an end-to-end learnable framework of extracting high-dimensional neighborhood-preserving embeddings, estimating locally linear transformations in the embedding space, and reconstructing shapes via divergence measure-based alignment of probabilistic density functions built over reconstructed and target shapes. Our approach enforces embeddings of shapes in correspondence to lie in the same universal/canonical embedding space, which eventually helps regularize the learning process and leads to a simple nearest neighbors approach between shape embeddings for finding reliable correspondences. Comprehensive experiments show that the new method makes noticeable improvements over state-of-the-art approaches on standard shape correspondence benchmark datasets covering both human and nonhuman shapes.
-
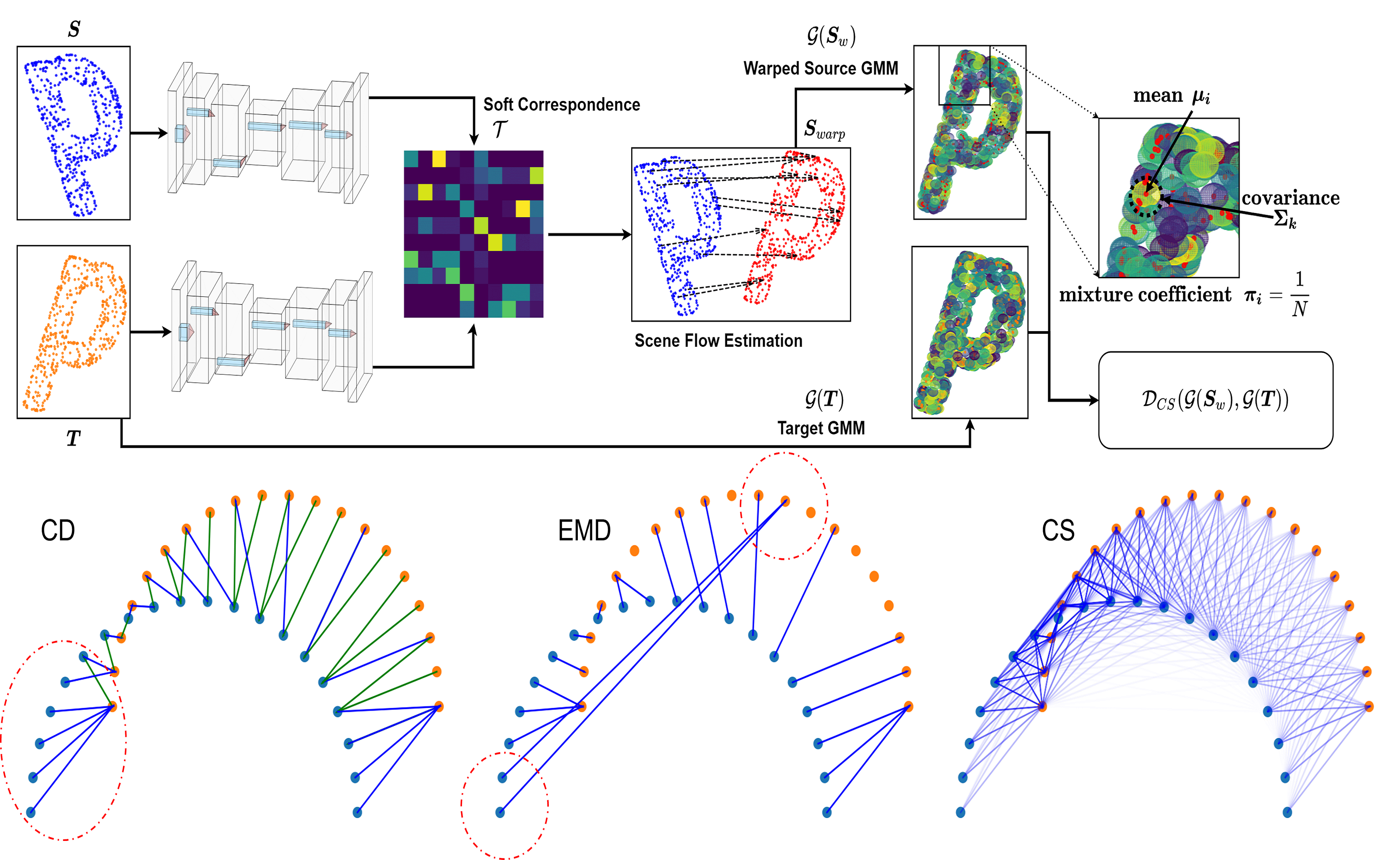
Self-Supervised Robust Scene Flow Estimation via the Alignment of Probability Density Functions
Pan He, Patrick Emami, Sanjay Ranka, Anand Rangarajan
AAAI Conference on Artificial Intelligence (AAAI), 2022
Paper Abstract Project page Bibtex
@article{he2022self,
title={Self-Supervised Robust Scene Flow Estimation via the Alignment of Probability Density Functions},
author={He, Pan and Emami, Patrick and Ranka, Sanjay and Rangarajan, Anand},
journal={arXiv preprint arXiv:2203.12193},
year={2022}
}
In this paper, we present a new self-supervised scene flow estimation approach for a pair of consecutive point clouds. The key idea of our approach is to represent discrete point clouds as continuous probability density functions using Gaussian mixture models. Scene flow estimation is therefore converted into the problem of recovering motion from the alignment of probability density functions, which we achieve using a closed-form expression of the classic Cauchy-Schwarz divergence. Unlike existing nearest-neighbor-based approaches that use hard pairwise correspondences, our proposed approach establishes soft and implicit point correspondences between point clouds and generates more robust and accurate scene flow in the presence of missing correspondences and outliers. Comprehensive experiments show that our method makes noticeable gains over the Chamfer Distance and the Earth Mover’s Distance in real-world environments and achieves state-of-the-art performance among selfsupervised learning methods on FlyingThings3D and KITTI, even outperforming some supervised methods with ground truth annotations
-
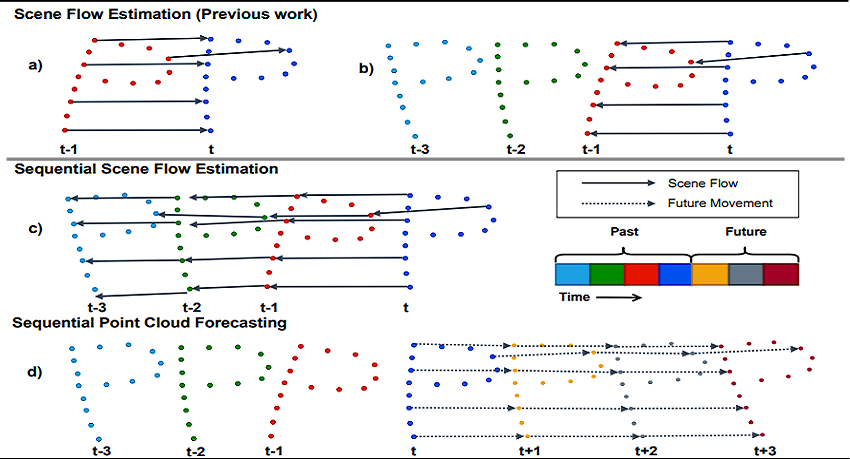
Learning Scene Dynamics from Point Cloud Sequences
Pan He, Patrick Emami, Sanjay Ranka, Anand Rangarajan
International Journal of Computer Vision (IJCV), 2021
Paper Abstract Project page Bibtex
Special Issue on 3D Computer Vision
@article{he2021learning,
title={Learning Scene Dynamics from Point Cloud Sequences},
author={He, Pan and Emami, Patrick and Ranka, Sanjay and Rangarajan, Anand},
journal={arXiv preprint arXiv:2111.08755},
year={2021}
}Understanding 3D scenes is a critical prerequisite for autonomous agents. Recently, LiDAR and other sensors have made large amounts of data available in the form of temporal sequences of point cloud frames. In this work, we propose a novel problem ---sequential scene flow estimation (SSFE)--- that aims to predict 3D scene flow for all pairs of point clouds in a given sequence. This is unlike the previously studied problem of scene flow estimation which focuses on two frames. We introduce the SPCM-Net architecture, which solves this problem by computing multi-scale spatiotemporal correlations between neighboring point clouds and then aggregating the correlation across time with an order-invariant recurrent unit. Our experimental evaluation confirms that recurrent processing of point cloud sequences results in significantly better SSFE compared to using only two frames. Additionally, we demonstrate that this approach can be effectively modified for sequential point cloud forecasting (SPF), a related problem that demands forecasting future point cloud frames. Our experimental results are evaluated using a new benchmark for both SSFE and SPF consisting of synthetic and real datasets. Previously, datasets for scene flow estimation have been limited to two frames. We provide non-trivial extensions to these datasets for multi-frame estimation and prediction. Due to the difficulty of obtaining ground truth motion for real-world datasets, we use self-supervised training and evaluation metrics. We believe that this benchmark will be pivotal to future research in this area. All code for benchmark and models will be made accessible at (https://github.com/BestSonny/SPCM).
-
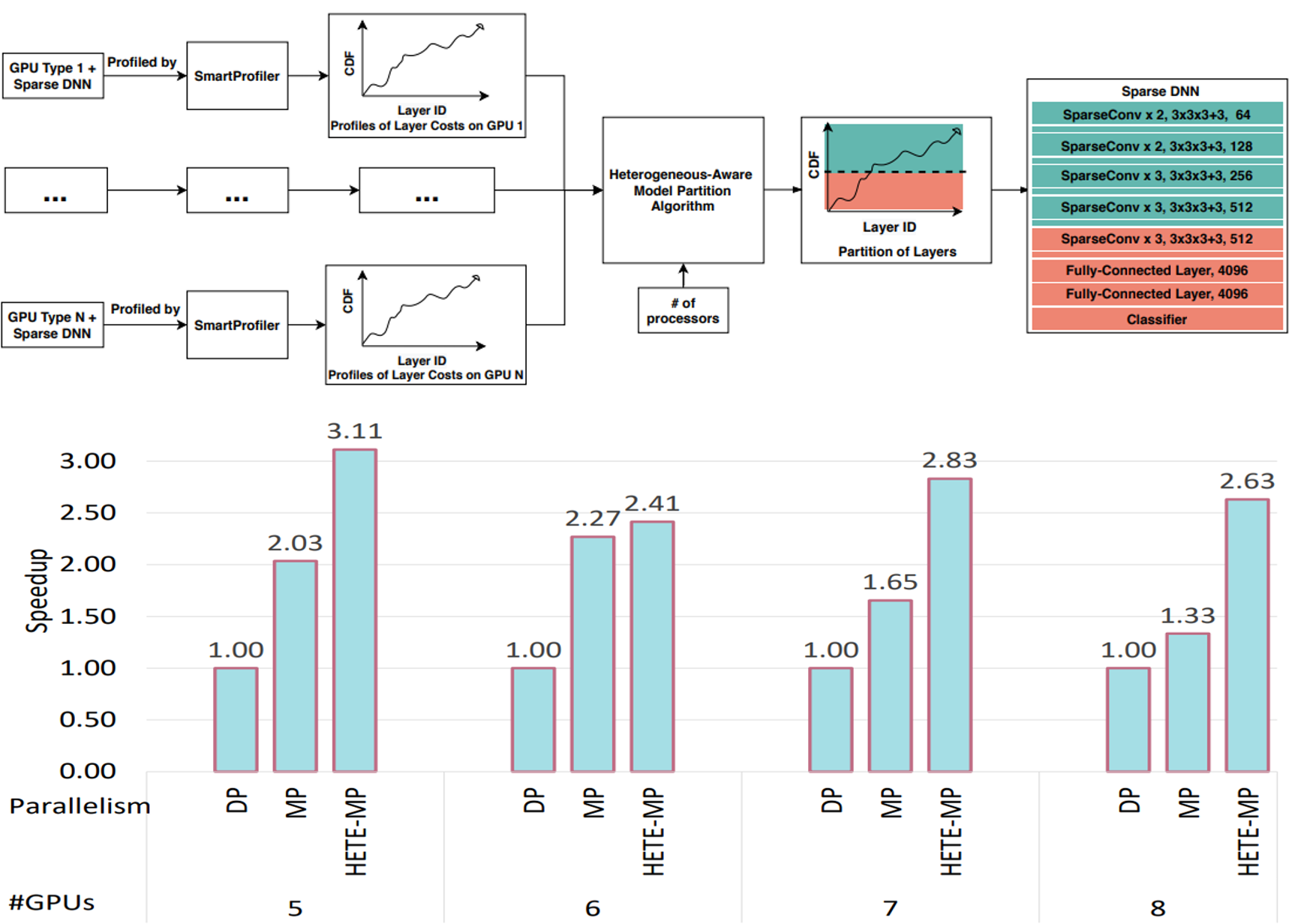
SparsePipe: Parallel Deep Learning for 3D Point Clouds
Keke Zhai*, Pan He*, Tania Banerjee, Anand Rangarajan, Sanjay Ranka
IEEE International Conference on High Performance Computing, Data, and Analytics (HiPC), 2020
Paper Abstract Project page Bibtex
@article{zhai2020sparsepipe,
title={SparsePipe: Parallel Deep Learning for 3D Point Clouds},
author={Zhai, Keke and He, Pan and Banerjee, Tania and Rangarajan, Anand and Ranka, Sanjay},
journal={arXiv preprint arXiv:2012.13846},
year={2020}
}We propose SparsePipe, an efficient and asynchronous parallelism approach for handling 3D point clouds with multi-GPU training. SparsePipe is built to support 3D sparse data such as point clouds. It achieves this by adopting generalized convolutions with sparse tensor representation to build expressive high-dimensional convolutional neural networks. Compared to dense solutions, the new models can efficiently process irregular point clouds without densely sliding over the entire space, significantly reducing the memory requirements and allowing higher resolutions of the underlying 3D volumes for better performance. SparsePipe exploits intra-batch parallelism that partitions input data into multiple processors and further improves the training throughput with inter-batch pipelining to overlap communication and computing. Besides, it suitably partitions the model when the GPUs are heterogeneous such that the computing is load-balanced with reduced communication overhead. Using experimental results on an eight-GPU platform, we show that SparsePipe can parallelize effectively and obtain better performance on current point cloud benchmarks for both training and inference, compared to its dense solutions.
Object-Centric Learning
-

Slot Order Matters for Compositional Scene Understanding
Patrick Emami, Pan He, Sanjay Ranka, Anand Rangarajan
Under Review
Paper Abstract Project page Bibtex
Empowering agents with a compositional understanding of their environment is a promising next step toward solving long-horizon planning problems. On the one hand, we have seen encouraging progress on variational inference algorithms for obtaining sets of object-centric latent representations (“slots”) from unstructured scene observations. On the other hand, generating scenes from slots has received less attention, in part because it is complicated by the lack of a canonical object order. A canonical object order is useful for learning the object correlations necessary to generate physically plausible scenes similar to how raster scan order facilitates learning pixel correlations for pixel-level autoregressive image generation. In this work, we address this lack by learning a fixed object order for a hierarchical variational autoencoder with a single level of autoregressive slots and a global scene prior. We cast autoregressive slot inference as a set-to-sequence modeling problem. We introduce an auxiliary loss to train the slot prior to generate objects in a fixed order. During inference, we align a set of inferred slots to the object order obtained from a slot prior rollout. To ensure the rolled out objects are meaningful for the given scene, we condition the prior on an inferred global summary of the input. Experiments on compositional environments and ablations demonstrate that our model with global prior, inference with aligned slot order, and auxiliary loss achieves state-of-the-art sample quality.
-
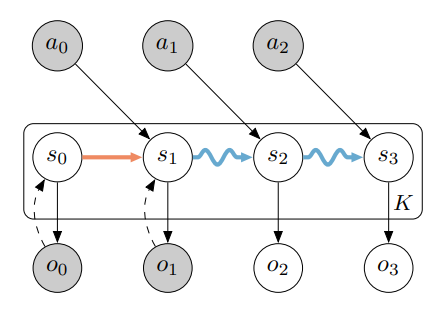
A Symmetric and Object-Centric World Model for Stochastic Environments
Patrick Emami, Pan He, Anand Rangarajan, Sanjay Ranka
NeurIPS Workshop on Object Representations for Learning and Reasoning (ORLR) (Oral), 2020
Paper Abstract Project page Bibtex
NeurIPS Workshop on Interpretable Inductive Biases and Physically Structured Learning (IBW), 2020
Object-centric world models learn useful representations for planning and control but have so far only been applied to synthetic and deterministic environments. We introduce a perceptual-grouping-based world model for the dual task of extracting object-centric representations and modeling stochastic dynamics in visually complex and noisy video environments. The world model is built upon a novel latent state space model that learns the variance for object discovery and dynamics separately. This design is motivated by the disparity in available information that exists between the discovery component, which takes a provided video frame and decomposes it into objects, and the dynamics component, which predicts representations for future video frames conditioned only on past frames. To learn the dynamics variance, we introduce a best-of-many-rollouts objective. We show that the world model successfully learns accurate and diverse rollouts in a real-world robotic manipulation environment with noisy actions while learning interpretable object-centric representations.
-
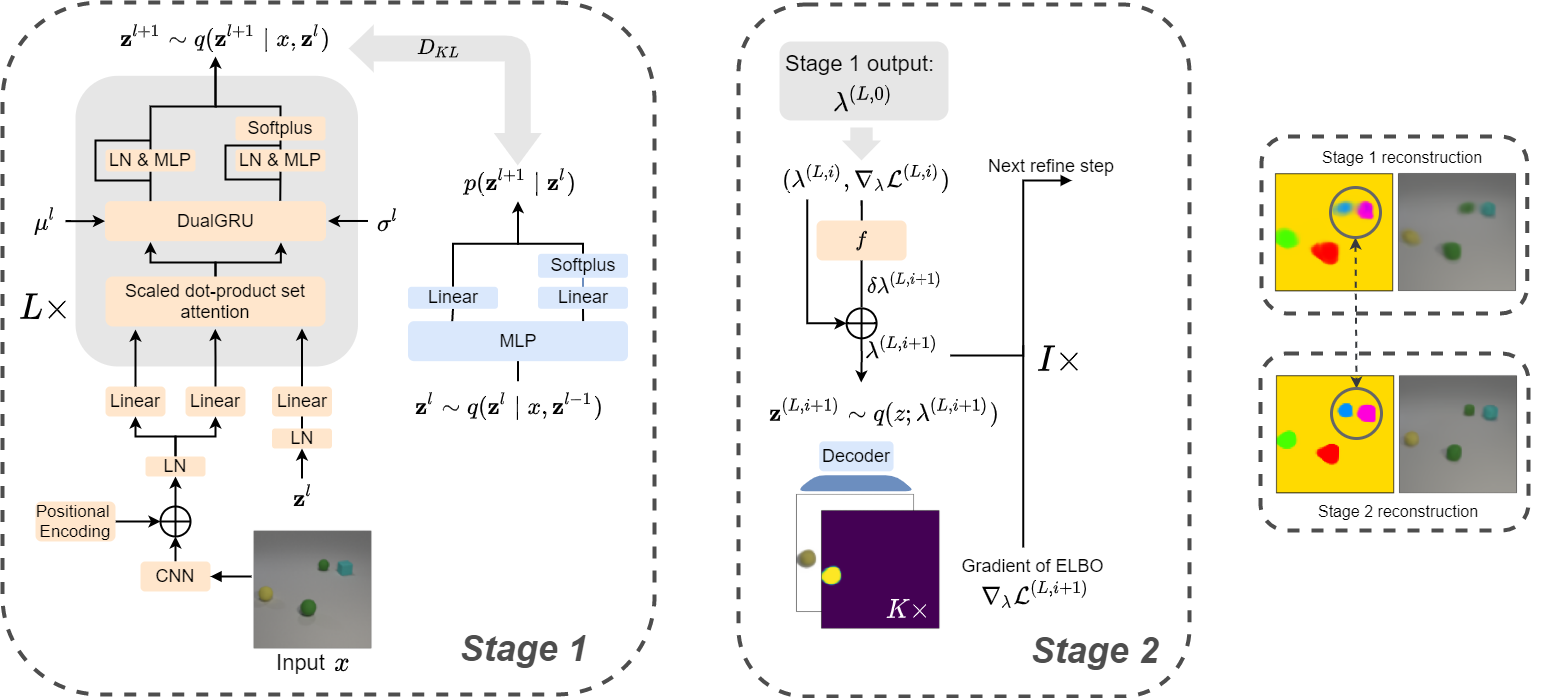
Efficient Iterative Amortized Inference for Learning Symmetric and Disentangled Multi-object Representations
Patrick Emami, Pan He, Sanjay Ranka, Anand Rangarajan
International Conference on Machine Learning (ICML), 2021
Paper Abstract Project page Bibtex
Unsupervised multi-object representation learning depends on inductive biases to guide the discovery of object-centric representations that generalize. However, we observe that methods for learning these representations are either impractical due to long training times and large memory consumption or forego key inductive biases. In this work, we introduce EfficientMORL, an efficient framework for the unsupervised learning of object-centric representations. We show that optimization challenges caused by requiring both symmetry and disentanglement can in fact be addressed by high-cost iterative amortized inference by designing the framework to minimize its dependence on it. We take a two-stage approach to inference: first, a hierarchical variational autoencoder extracts symmetric and disentangled representations through bottom-up inference, and second, a lightweight network refines the representations with top-down feedback. The number of refinement steps taken during training is reduced following a curriculum, so that at test time with zero steps the model achieves 99.1% of the refined decomposition performance. We demonstrate strong object decomposition and disentanglement on the standard multi-object benchmark while achieving nearly an order of magnitude faster training and test time inference over the previous state-of-the-art model.
Trustworthy AI & Security
-

Adaptive Adversarial Attack on Scene Text Recognition
Xiaoyong Yuan, Pan He, Xiaolin Li, Dapeng Oliver Wu
The Eighth International Workshop on Security and Privacy in Big Data in conjunction with IEEE INFOCOM, 2020
Paper Abstract Project page Bibtex
@inproceedings{yuan2020adaptive,
title={Adaptive adversarial attack on scene text recognition},
author={Yuan, Xiaoyong and He, Pan and Lit, Xiaolin and Wu, Dapeng},
booktitle={IEEE INFOCOM 2020-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS)},
pages={358--363},
year={2020},
organization={IEEE}
}Recent studies have shown that state-of-the-art deep learning models are vulnerable to the inputs with small perturbations (adversarial examples). We observe two critical obstacles in adversarial examples: (i) Recent adversarial attacks require manually tuning hyper-parameters and take a long time to construct an adversarial example, making it impractical to attack real-time systems; (ii) Most of the studies focus on nonsequential tasks, such as image classification, yet only a few consider sequential tasks. In this work, we propose an adaptive approach to speed up adversarial attacks, especially on sequential learning tasks. By leveraging the uncertainty of each task, we directly learn the adaptive multi-task weightings, without manually searching hyper-parameters. A unified architecture is developed and evaluated for both non-sequential tasks and sequential ones. To evaluate the effectiveness, we take the scene text recognition task as a case study. To our best knowledge, our proposed method is the first attempt to adversarial attack for scene text recognition. Adaptive Attack achieves over 99.9% success rate with 3 ∼ 6× speedup compared to state-of-the-art adversarial attacks.
-
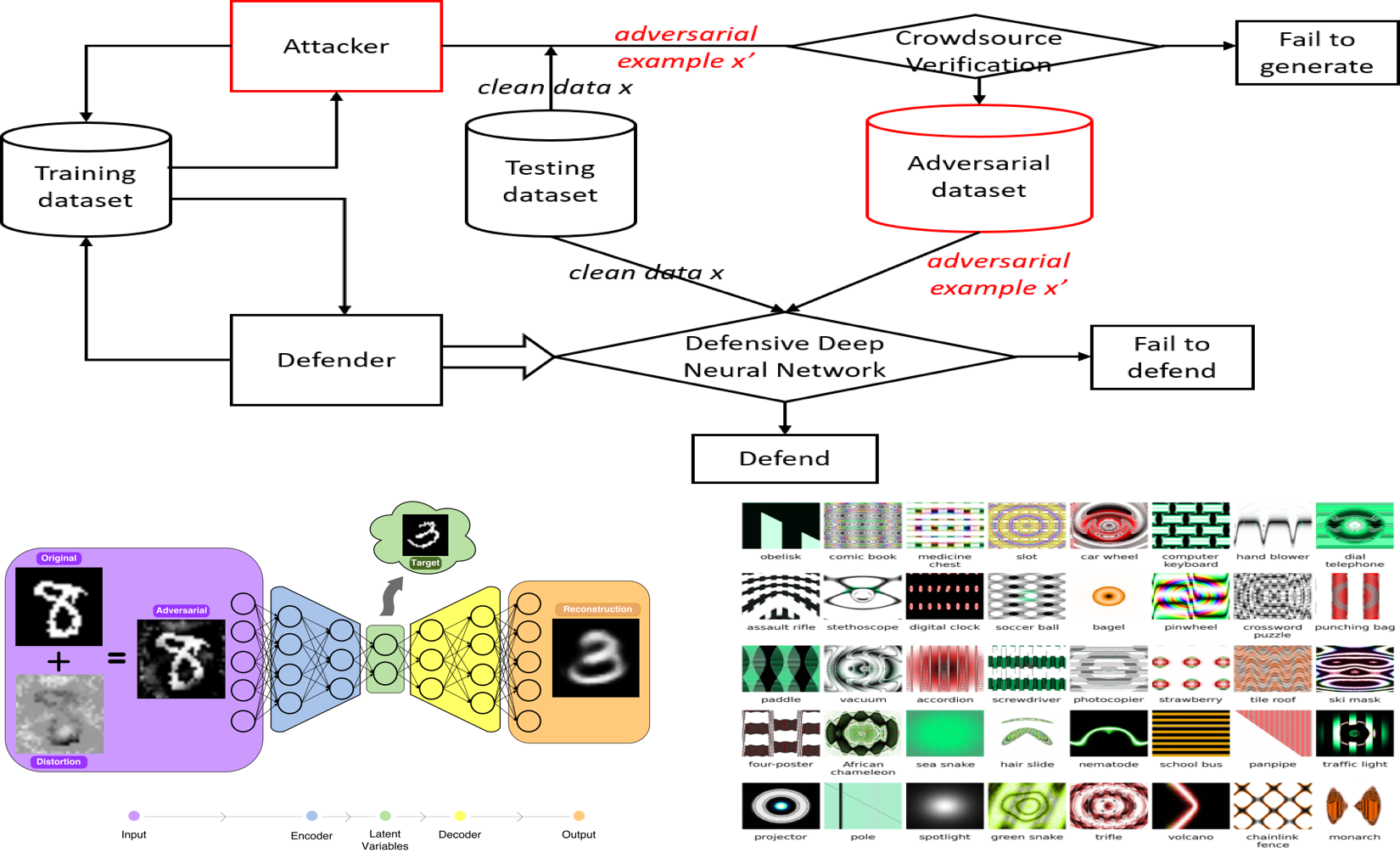
Adverarial Examples: Attacks and Defenses for Deep Learning
Xiaoyong Yuan, Pan He, Qile Zhu, Xiaolin Li
IEEE Transactions on Neural Networks and Learning Systems (TNNLS)
Paper Abstract Project page Bibtex
Top-5 Popular Articles in TNNLS up to date
@article{yuan2019adversarial,
title={Adversarial examples: Attacks and defenses for deep learning},
author={Yuan, Xiaoyong and He, Pan and Zhu, Qile and Li, Xiaolin},
journal={IEEE transactions on neural networks and learning systems},
volume={30},
number={9},
pages={2805--2824},
year={2019},
publisher={IEEE}
}With rapid progress and significant successes in a wide spectrum of applications, deep learning is being applied in many safety-critical environments. However, deep neural networks (DNNs) have been recently found vulnerable to well-designed input samples called adversarial examples. Adversarial perturbations are imperceptible to human but can easily fool DNNs in the testing/deploying stage. The vulnerability to adversarial examples becomes one of the major risks for applying DNNs in safety-critical environments. Therefore, attacks and defenses on adversarial examples draw great attention. In this paper, we review recent findings on adversarial examples for DNNs, summarize the methods for generating adversarial examples, and propose a taxonomy of these methods. Under the taxonomy, applications for adversarial examples are investigated. We further elaborate on countermeasures for adversarial examples. In addition, three major challenges in adversarial examples and the potential solutions are discussed.
-
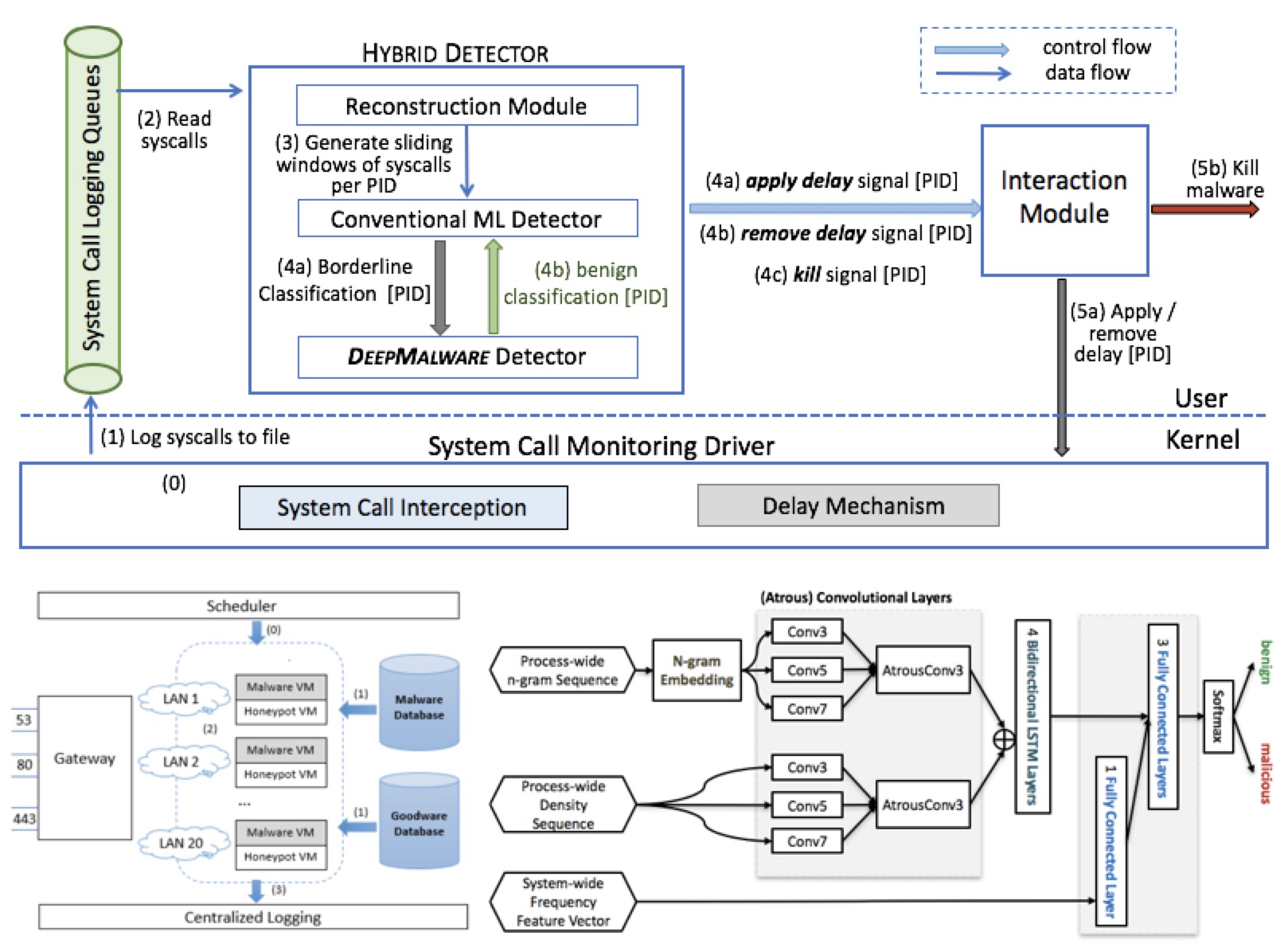
Learning Fast and Slow: PROPEDEUTICA for Real-time Malware Detection
Ruimin Sun*, Xiaoyong Yuan*, Pan He, Qile Zhu, Aokun Chen, Andre Gregio, Daniela Oliveira, Xiaolin Li
IEEE Transactions on Neural Networks and Learning Systems (TNNLS)
Paper Abstract Project page Bibtex
@article{sun2017learning,
title={Learning fast and slow: Propedeutica for real-time malware detection},
author={Sun, Ruimin and Yuan, Xiaoyong and He, Pan and Zhu, Qile and Chen, Aokun and Gregio, Andre and Oliveira, Daniela and Li, Xiaolin},
journal={arXiv preprint arXiv:1712.01145},
year={2017}
}In this paper, we introduce and evaluate PROPEDEUTICA, a novel methodology and framework for efficient and effective real-time malware detection, leveraging the best of conventional machine learning (ML) and deep learning (DL) algorithms. In PROPEDEUTICA, all software processes in the system start execution subjected to a conventional ML detector for fast classification. If a piece of software receives a borderline classification, it is subjected to further analysis via more performance expensive and more accurate DL methods, via our newly proposed DL algorithm DEEPMALWARE. Further, in an exploratory fashion, we introduce delays to the execution of software subjected to DEEPMALWARE as a way to “buy time” for DL analysis and to rate-limit the impact of possible malware in the system. We evaluated PROPEDEUTICA with a set of 9,115 malware samples and 877 commonly used benign software samples from various categories for the Windows OS. Our results show that the false positive rate for conventional ML methods can reach 20%, and for modern DL methods it is usually below 6%. However, the classification time for DL can be 100X longer than conventional ML methods. PROPEDEUTICA improved the detection F1-score from 77.54% (conventional ML method) to 90.25% (16.39% increase), and reduced the detection time by 54.86%. Further, the percentage of software subjected to DL analysis was approximately 40% on average. Further, the application of delays in software subjected to ML reduced the detection time by approximately 10%. Finally, we found and discussed a discrepancy between the detection accuracy offline (analysis after all traces are collected) and on-the-fly (analysis in tandem with trace collection). Conventional ML experienced a decrease of 13% in accuracy when executed offline (89.05%) compared to online (77.54%) with the same traces. Our insights show that conventional ML and modern DLbased malware detectors in isolation cannot meet the needs of efficient and effective malware detection: high accuracy, low false positive rate, and short classification time.
Scene Text and Scene Understanding
-

Ego-Deliver: A Large-Scale Dataset for Egocentric Video Analysis
Haonan Qiu, Pan He, Shuchun Liu, Weiyuan Shao, Feiyun Zhang, Jiajun Wang, Liang He, Feng Wang
ACM International Conference on Multimedia (ACM-MM), 2021
Paper Abstract Project page Bibtex
@inproceedings{qiu2021ego,
title={Ego-Deliver: A Large-Scale Dataset for Egocentric Video Analysis},
author={Haonan Qiu, Pan He, Shuchun Liu, Weiyuan Shao, Feiyun Zhang, Jiajun Wang, Liang He, Feng Wang},
booktitle={ACM International Conference on Multimedia (ACM-MM)},
year={2021}
}The egocentric video provides a unique view of event participants to show their attention, vision, and interaction with objects. In this paper, we introduce Ego-Deliver, a new large-scale egocentric video benchmark recorded by takeaway riders about their daily work. To the best of our knowledge, Ego-Deliver presents the first attempt in understanding activities from the takeaway delivery process while being one of the largest egocentric video action datasets to date. Our dataset provides a total of 5,360 videos with more than 139,000 multi-track annotations and 45 different attributes, which we believe is pivotal to future research in this area. We introduce the FS-Net architecture, a new anchor-free action detection approach handling extreme variations of action durations. We partition videos into fragments and build dynamic graphs over fragments, where multi-fragment context information is aggregated to boost fragment classification. A splicing and scoring module is applied to obtain final action proposals. Our experimental evaluation confirms that the proposed framework outperforms existing approaches on the proposed Ego-Deliver benchmark and is competitive on other popular benchmarks. In our current version, Ego-Deliver is used to make a comprehensive comparison between algorithms for activity detection. We also show its application to action recognition with promising results. The dataset, toolkits and baseline results will be made available at https://github.com/EgoDeliver/EgoDeliver_Dataset.
-
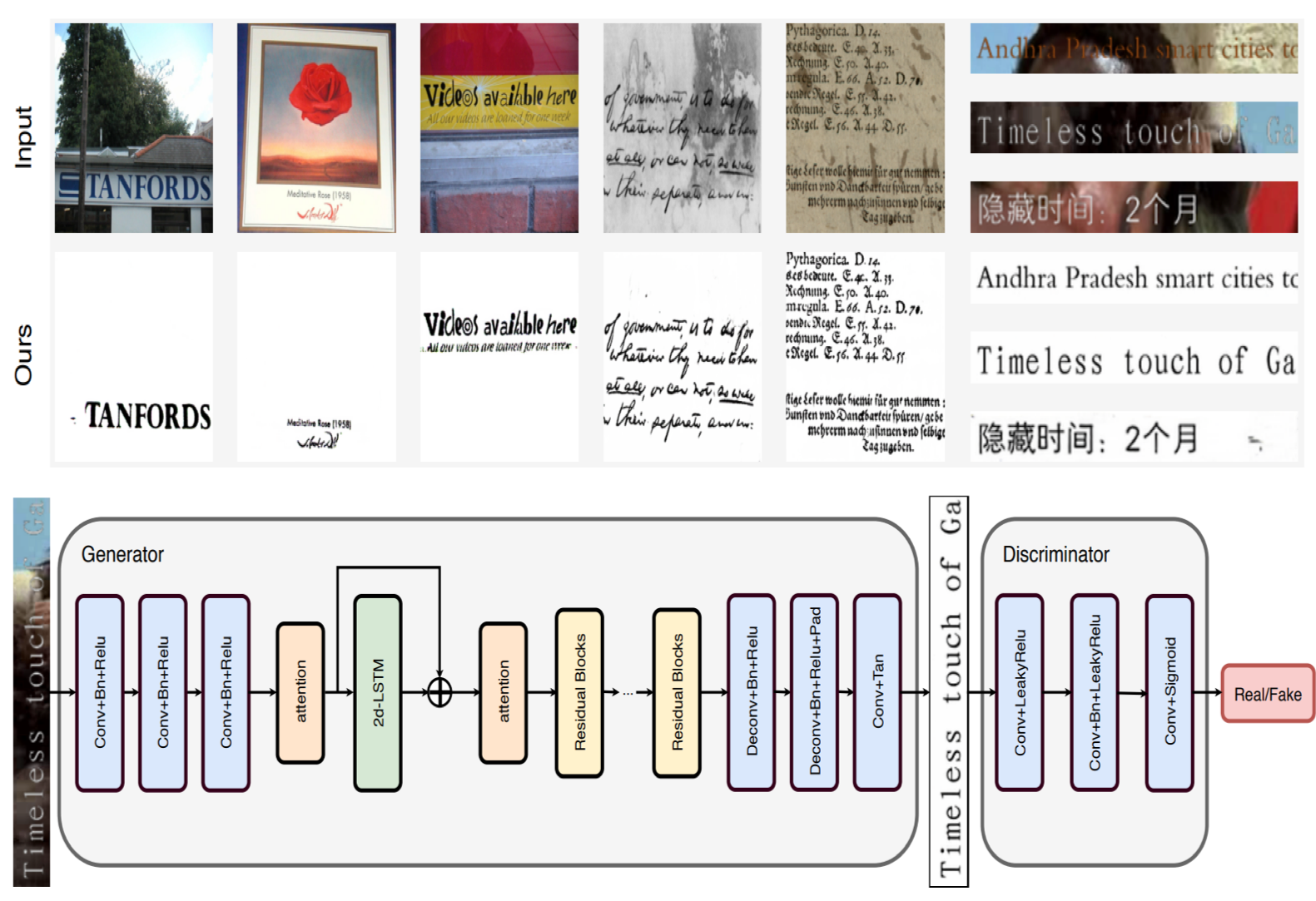
Document Binarization using Recurrent Attention Generative Model
Shuchun Liu, Feiyun Zhang, Mingxi Chen, Yufei Xie, Pan He, Jie Shao
British Machine Vision Conference (BMVC), 2019
Paper Abstract Project page Bibtex
@inproceedings{liu2019document,
title={Document Binarization using Recurrent Attention Generative Model},
author={Liu, Shuchun and Zhang, Feiyun and Chen, MingXi and Xie, YuFei and He, Pan and Shao, Jie},
booktitle={The British Machine Vision Conference (BMVC)},
pages={95},
year={2019}
}We develop a general deep learning approach, by introducing a recurrent attention generative model with adversarial training to do image binarization which is an elementary pre-processing step in the document image analysis and recognition pipeline. The document binarization using recurrent attention generative(DB-RAM) model comprises three contributions: First, to suppress the interference from complex background, non-local attention blocks are incorporated to capture spatial long-range dependencies. Second, we explore the use of Spatial Recurrent Neural Networks (SRNNs) to pass spatially varying contextual information across an image, which leverages the prior knowledge of text orientation and semantics. Third, to validate the effectiveness of our proposed method, we further synthetically generate two comprehensive subtitle datasets that cover various real-world conditions. Evaluated on various standard benchmarks, our proposed method significantly outperforms state-of-the-art binarization methods both quantitatively and qualitatively. The supplementary material also shows that the proposed method improves the recognition rate and also performs well in the task of image unshadowing, which evidently verifies its generality
-

Boosting up Scene Text Detectors with Guided CNN
Xiaoyu Yue, Zhanghui Kuang, Zhaoyang Zhang, Zhenfang Chen, Pan He, Yu Qiao, Wei Zhang
British Machine Vision Conference (BMVC), 2019
Paper Abstract Project page Bibtex
Accepted for (Oral) presentation, 4.29% acceptance rate
@inproceedings{YueKZCH0Z18,
author={Xiaoyu Yue and Zhanghui Kuang and Zhaoyang Zhang and Zhenfang Chen and Pan He and Yu Qiao and Wei Zhang},
title={Boosting up Scene Text Detectors with Guided CNN},
year={2018},
pages={307},
booktitle={The British Machine Vision Conference (BMVC)},
}Deep CNNs have achieved great success in text detection. Most of existing methods attempt to improve accuracy with sophisticated network design, while paying less attention on speed. In this paper, we propose a general framework for text detection called Guided CNN to achieve the two goals simultaneously. The proposed model consists of one guidance subnetwork, where a guidance mask is learned from the input image itself, and one primary text detector, where every convolution and non-linear operation are conducted only in the guidance mask. On the one hand, the guidance subnetwork filters out non-text regions coarsely, greatly reduces the computation complexity. On the other hand, the primary text detector focuses on distinguishing between text and hard nontext regions and regressing text bounding boxes, achieves a better detection accuracy. A training strategy, called background-aware block-wise random synthesis, is proposed to further boost up the performance. We demonstrate that the proposed Guided CNN is not only effective but also efficient with two state-of-the-art methods, CTPN [52] and EAST [64], as backbones. On the challenging benchmark ICDAR 2013, it speeds up CTPN by 2.9 times on average, while improving the F-measure by 1.5%. On ICDAR 2015, it speeds up EAST by 2.0 times while improving the F-measure by 1.0%.
-
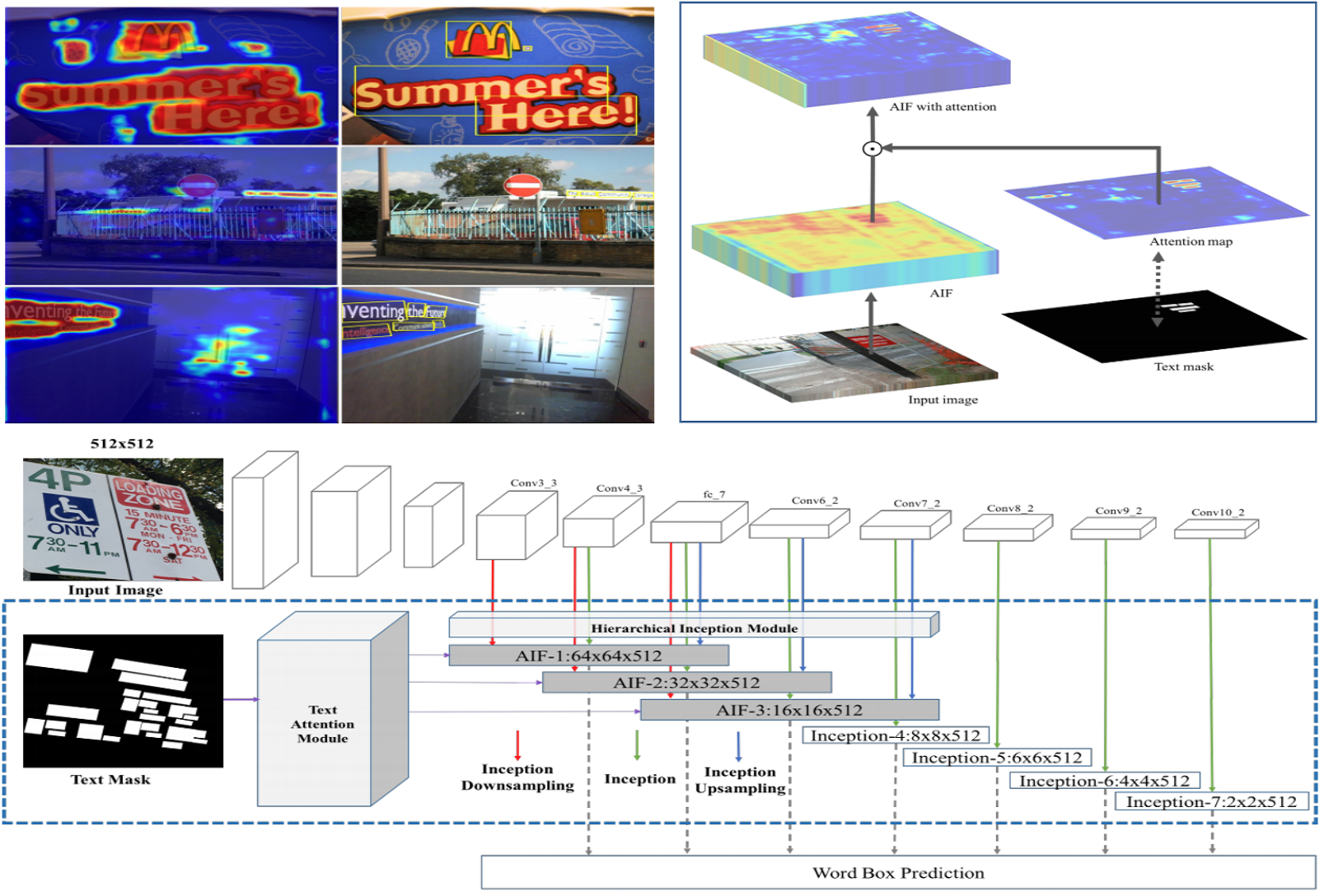
Single Shot Text Detector with Regional Attention
Pan He, Weilin Huang, Tong He, Qile Zhu, Yu Qiao, Xiaolin Li
IEEE International Conference on Computer Vision (ICCV), 2017
Paper Abstract Project page Bibtex
Accepted for (Spotlight) presentation, 2.61% acceptance rate
@inproceedings{he2017single,
title={Single shot text detector with regional attention},
author={He, Pan and Huang, Weilin and He, Tong and Zhu, Qile and Qiao, Yu and Li, Xiaolin},
booktitle={Proceedings of the IEEE international conference on computer vision},
pages={3047--3055},
year={2017}
}We present a novel single-shot text detector that directly outputs word-level bounding boxes in a natural image. We propose an attention mechanism which roughly identifies text regions via an automatically learned attentional map. This substantially suppresses background interference in the convolutional features, which is the key to producing accurate inference of words, particularly at extremely small sizes. This results in a single model that essentially works in a coarse-to-fine manner. It departs from recent FCNbased text detectors which cascade multiple FCN models to achieve an accurate prediction. Furthermore, we develop a hierarchical inception module which efficiently aggregates multi-scale inception features. This enhances local details, and also encodes strong context information, allowing the detector to work reliably on multi-scale and multiorientation text with single-scale images. Our text detector achieves an F-measure of 77% on the ICDAR 2015 benchmark, advancing the state-of-the-art results
-

Detecting Text in Natural Image with Connectionist Text Proposal Network
Zhi Tian, Weilin Huang, Tong He, Pan He, Yu Qiao
European Conference on Computer Vision (ECCV), 2016
Paper Abstract Project page Bibtex
@inproceedings{tian2016detecting,
title={Detecting text in natural image with connectionist text proposal network},
author={Tian, Zhi and Huang, Weilin and He, Tong and He, Pan and Qiao, Yu},
booktitle={European conference on computer vision},
pages={56--72},
year={2016},
organization={Springer}
}We propose a novel Connectionist Text Proposal Network (CTPN) that accurately localizes text lines in natural image. The CTPN detects a text line in a sequence of fine-scale text proposals directly in convolutional feature maps. We develop a vertical anchor mechanism that jointly predicts location and text/non-text score of each fixed-width proposal, considerably improving localization accuracy. The sequential proposals are naturally connected by a recurrent neural network, which is seamlessly incorporated into the convolutional network, resulting in an end-to-end trainable model. This allows the CTPN to explore rich context information of image, making it powerful to detect extremely ambiguous text. The CTPN works reliably on multi-scale and multilanguage text without further post-processing, departing from previous bottom-up methods requiring multi-step post filtering. It achieves 0.88 and 0.61 F-measure on the ICDAR 2013 and 2015 benchmarks, surpassing recent results [8, 35] by a large margin. The CTPN is computationally efficient with 0.14s/image, by using the very deep VGG16 model [27]. Online demo is available at: http://textdet.com/.
-

Reading Scene Text in Deep Convolutional Sequences
Pan He*, Weilin Huang*, Yu Qiao, Chen Change Loy, Xiaoou Tang
The 30th AAAI Conference on Artificial Intelligence (AAAI), 2016 (Oral)
Paper Abstract Project page Bibtex
@inproceedings{he2016reading,
title={Reading scene text in deep convolutional sequences},
author={He, Pan and Huang, Weilin and Qiao, Yu and Loy, Chen and Tang, Xiaoou},
booktitle={Proceedings of the AAAI conference on artificial intelligence},
volume={30},
number={1},
year={2016}
}We develop a Deep-Text Recurrent Network (DTRN) that regards scene text reading as a sequence labelling problem. We leverage recent advances of deep convolutional neural networks to generate an ordered highlevel sequence from a whole word image, avoiding the difficult character segmentation problem. Then a deep recurrent model, building on long short-term memory (LSTM), is developed to robustly recognize the generated CNN sequences, departing from most existing approaches recognising each character independently. Our model has a number of appealing properties in comparison to existing scene text recognition methods: (i) It can recognise highly ambiguous words by leveraging meaningful context information, allowing it to work reliably without either pre- or post-processing; (ii) the deep CNN feature is robust to various image distortions; (iii) it retains the explicit order information in word image, which is essential to discriminate word strings; (iv) the model does not depend on pre-defined dictionary, and it can process unknown words and arbitrary strings. It achieves impressive results on several benchmarks, advancing the-state-of-the-art substantially
Intelligent Transportation
-

Machine Learning-based Highway Truck Commodity Classification Using Logo Data
Pan He*, Aotian Wu*, Xiaohui Huang, Anand Rangarajan, Sanjay Ranka
Applied Sciences, 2022
Paper Abstract Project page Bibtex
@article{he2022machine,
title={Machine Learning-Based Highway Truck Commodity Classification Using Logo Data},
author={He, Pan and Wu, Aotian and Huang, Xiaohui and Rangarajan, Anand and Ranka, Sanjay},
journal={Applied Sciences},
volume={12},
number={4},
pages={2075},
year={2022},
publisher={MDPI}
}
In this paper, we propose a novel approach to commodity classification from surveillance videos by utilizing logo data on trucks. Broadly, most logos can be classified as predominantly text or predominantly images. For the former, we leverage state-of-the-art deep-learning-based text recognition algorithms on images. For the latter, we develop a two-stage image retrieval algorithm consisting of a universal logo detection stage that outputs all potential logo positions, followed by a logo recognition stage designed to incorporate advanced image representations. We develop an integrated approach to combine predictions from both the text-based and image-based solutions, which can help determine the commodity type that is potentially being hauled by trucks. We evaluated these models on videos collected in collaboration with the state transportation entity and achieved promising performance. This, along with prior work on trailer classification, can be effectively used for automatically deriving commodity types for trucks moving on highways.
-
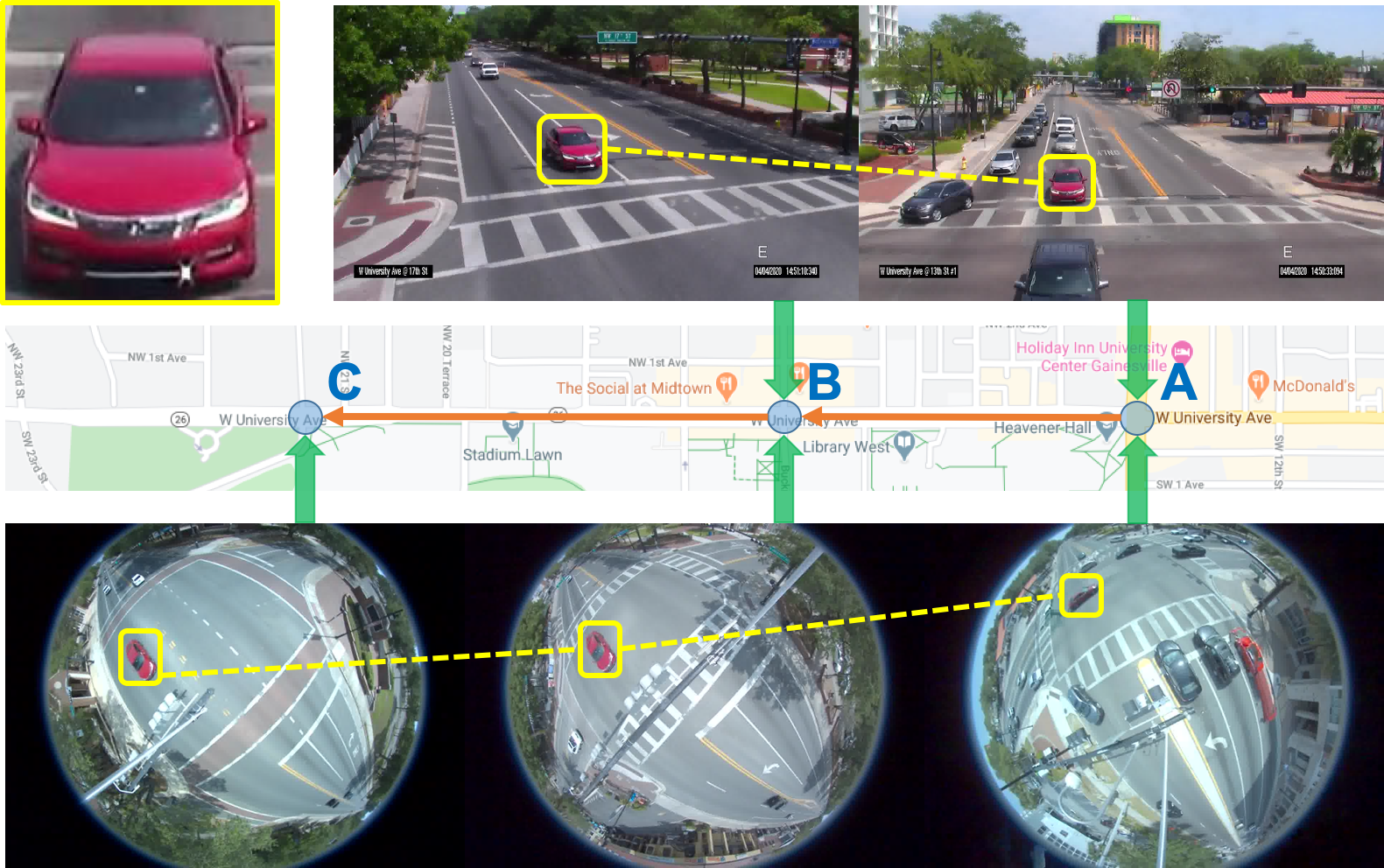
Machine Learning based Real-time Multi-Camera Vehicle Tracking and Travel Time Estimation
Xiaohui Huang, Pan He, Anand Rangarajan, Sanjay Ranka
Journal of Imaging, 2022
Paper Abstract Project page Bibtex
@article{huang2022machine,
title={Machine-learning-based real-time multi-camera vehicle tracking and travel-time estimation},
author={Huang, Xiaohui and He, Pan and Rangarajan, Anand and Ranka, Sanjay},
journal={Journal of imaging},
volume={8},
number={4},
pages={101},
year={2022},
publisher={MDPI}
}
Travel-time estimation of traffic flow is an important problem with critical implications for traffic congestion analysis. We developed techniques for using intersection videos to identify vehicle trajectories across multiple cameras and analyze corridor travel time. Our approach consists of (1) multi-object single-camera tracking, (2) vehicle re-identification among different cameras, (3) multi-object multi-camera tracking, and (4) travel-time estimation. We evaluated the proposed framework on real intersections in Florida with pan and fisheye cameras. The experimental results demonstrate the viability and effectiveness of our method.
-

Automated Truck Taxonomy Classification Using Deep Convolutional Neural Networks
Abdullah Almutairi*, Pan He*, Anand Rangarajan, Sanjay Ranka
International Journal of Intelligent Transportation Systems Research (IJIT), 2022
Paper Abstract Project page Bibtex
@article{almutairi2022automated,
title={Automated Truck Taxonomy Classification Using Deep Convolutional Neural Networks},
author={Almutairi, Abdullah and He, Pan and Rangarajan, Anand and Ranka, Sanjay},
journal={International Journal of Intelligent Transportation Systems Research},
pages={1--12},
year={2022},
publisher={Springer}
}
Trucks are the key transporters of freight. The types of commodities and goods mainly determine the right trailer for carrying them. Furthermore, fnding the commodities’ fow is an important task for transportation agencies in better planning freight infrastructure investments and initiating near-term trafc throughput improvements. In this paper, we propose a fnegrained deep learning based truck classifcation system that can detect and classify the trucks, tractors, and trailers following the Federal Highway Administration’s (FHWA) vehicle schema. We created a large, fne-grained labeled dataset of vehicle images collected from state highways. Experimental results show the high accuracy of our system and visualize the salient features of the trucks that infuence classifcation.
-
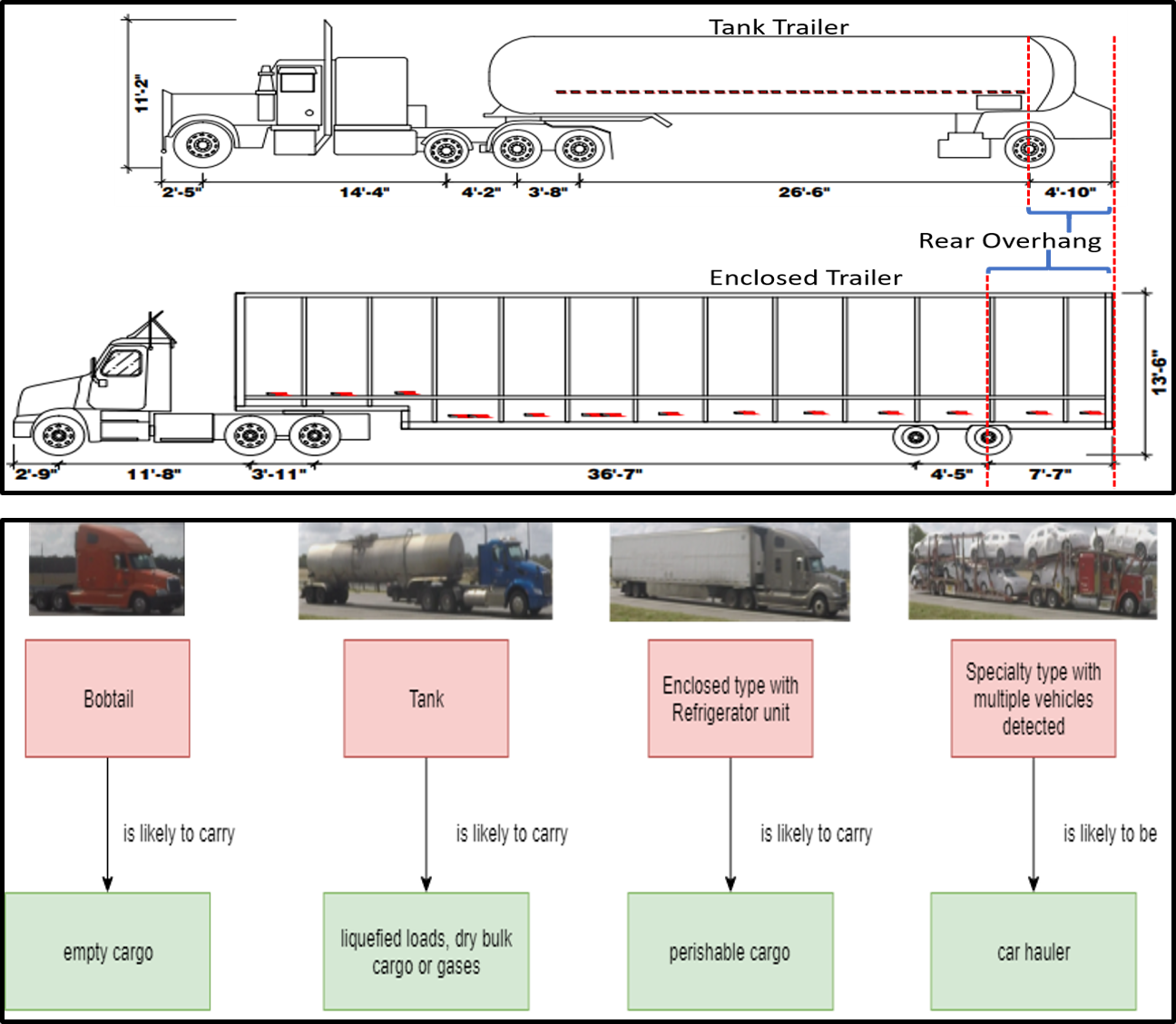
Video-based Machine Learning System for Commodity Classification
Pan He, Aotian Wu, Xiaohui Huang, Anand Rangarajan, Sanjay Ranka
Vehicle Technology and Intelligent Transportation System (VEHITS), 2020
Paper Abstract Project page Bibtex
@inproceedings{he2020video,
title={Video-based Machine Learning System for Commodity Classification},
author={He, Pan and Wu, Aotian and Huang, Xiaohui and Rangarajan, Anand and Ranka, Sanjay},
booktitle={Vehicle Technology and Intelligent Transportation System (VEHITS)},
year={2020}
}The cost of video cameras is decreasing rapidly while their resolution is improving. This makes them useful for a number of transportation applications. In this paper, we present an approach to commodity classification from surveillance videos by utilizing text information of logos on trucks. A new real-world benchmark dataset is collected and annotated accordingly that covers over 4,000 truck images. Our approach is evaluated on video data collected in collaboration with the state transportation entity. Results on this dataset indicate that our proposed approach achieved promising performance. This, along with prior work on trailer classification, can be effectively used for automatically deriving the commodity classification for trucks moving on highways using video collection and processing.
-

Truck and Trailer Classification with Deep Learning Based Geometric Features
Pan He, Aotian Wu, Xiaohui Huang, Jerry Scott, Anand Rangarajan, Sanjay Ranka
IEEE Transactions on Intelligent Transportation Systems (T-ITS), 2019
Paper Abstract Project page Bibtex
@article{he2020truck,
title={Truck and Trailer Classification With Deep Learning Based Geometric Features},
author={He, Pan and Wu, Aotian and Huang, Xiaohui and Scott, Jerry and Rangarajan, Anand and Ranka, Sanjay},
journal={IEEE Transactions on Intelligent Transportation Systems},
year={2020},
publisher={IEEE}
}In this paper, we present a novel and effective approach to truck and trailer classification, which integrates deep learning models and conventional image processing and computer vision techniques. The developed method groups trucks into subcategories by carefully examining the truck classes and identifying key geometric features for discriminating truck and trailer types. We also present three discriminating features that involve shape, texture, and semantic information to identify trailer types. Experimental results demonstrate that the developed hybrid approach can achieve high accuracy with limited training data, where the vanilla deep learning approaches show moderate performance due to over-fitting and poor generalization. Additionally, the models generated are human-understandable.
-

Deep Learning based Geometric Features for Effective Truck Selection and Classification from Highway Videos
Pan He, Aotian Wu, Xiaohui Huang, Jerry Scott, Anand Rangarajan, Sanjay Ranka
Intelligent Transportation Systems Conference (ITSC), 2019
Paper Abstract Project page Bibtex
@inproceedings{he2019deep,
title={Deep Learning based Geometric Features for Effective Truck Selection and Classification from Highway Videos},
author={He, Pan and Wu, Aotian and Huang, Xiaohui and Scott, Jerry and Rangarajan, Anand and Ranka, Sanjay},
booktitle={2019 IEEE Intelligent Transportation Systems Conference (ITSC)},
pages={824--830},
year={2019},
organization={IEEE}
}Freight analysis creates a comprehensive picture of freight movements across the state (and country), by capturing and gathering a variety of sources. Understanding and predicting freight flow patterns is useful in planning and policy decisions at the federal, state, and local levels.
Trucks are largely in charge of transporting freight, both in terms of tonnage and revenue. The Federal Highway Administration (FHWA) has a methodology for classifying these trucks into nine categories. Determining the class of the truck is useful in understanding the type of commodity that truck is carrying. This paper details a video based machine learning approach for truck classification. Our approach uses an array of techniques from image processing, deep learning and data mining to develop highly accurate classifiers. Additionally, we provide mechanisms for automatically filtering out trucks from video data.
-
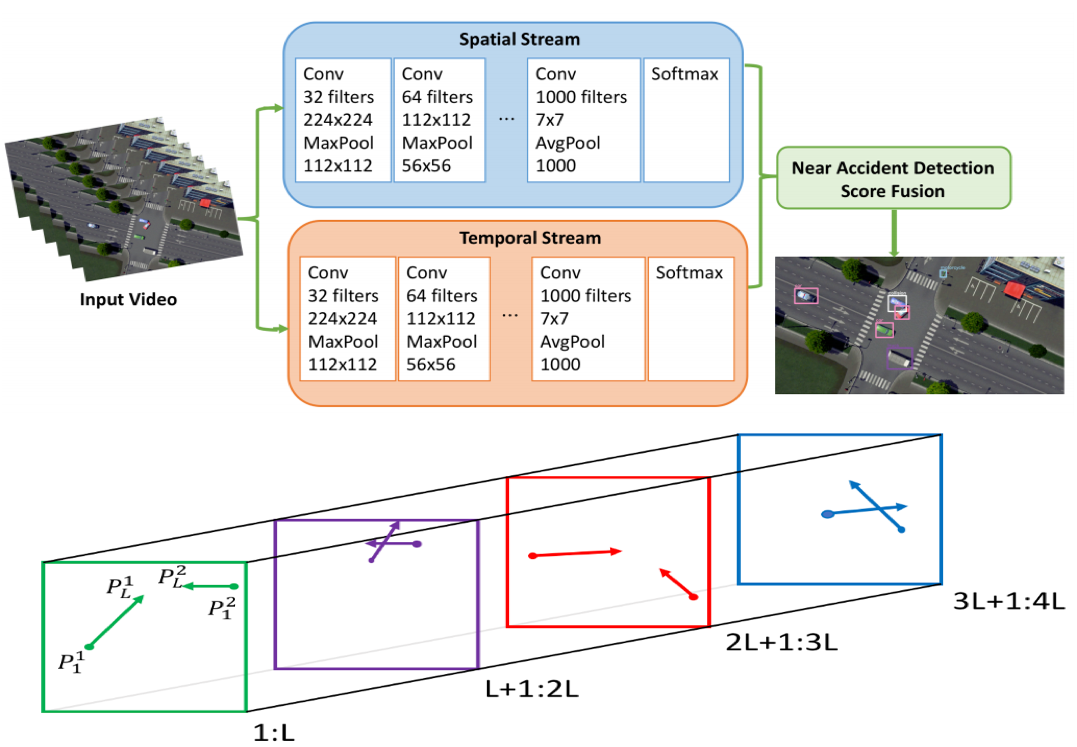
Intelligent Intersection: Two-Stream Convolutional Networks for Real-time Near Accident Detection in Traffic Video
Xiaohui Huang, Pan He, Anand Rangarajan, Sanjay Ranka
ACM Transactions on Spatial Algorithms and Systems (TSAS)
Paper Abstract Project page Bibtex
@article{huang2020intelligent,
title={Intelligent intersection: two-stream convolutional networks for real-time near-accident detection in traffic video},
author={Huang, Xiaohui and He, Pan and Rangarajan, Anand and Ranka, Sanjay},
journal={ACM Transactions on Spatial Algorithms and Systems (TSAS)},
volume={6},
number={2},
pages={1--28},
year={2020},
publisher={ACM New York, NY, USA}
}In Intelligent Transportation System, real-time systems that monitor and analyze road users become increasingly critical as we march toward the smart city era. Vision-based frameworks for Object Detection, Multiple Object Tracking, and Traffic Near Accident Detection are important applications of Intelligent Transportation System, particularly in video surveillance and etc. Although deep neural networks have recently achieved great success in many computer vision tasks, a uniformed framework for all the three tasks is still challenging where the challenges multiply from demand for real-time performance, complex urban setting, highly dynamic traffic event, and many traffic movements. In this paper, we propose a two-stream Convolutional Network architecture that performs real-time detection, tracking, and near accident detection of road users in traffic video data. The two-stream model consists of a spatial stream network for Object Detection and a temporal stream network to leverage motion features for Multiple Object Tracking. We detect near accidents by incorporating appearance features and motion features from two-stream networks. Using aerial videos, we propose a Traffic Near Accident Dataset (TNAD) covering various types of traffic interactions that is suitable for vision-based traffic analysis tasks. Our experiments demonstrate the advantage of our framework with an overall competitive qualitative and quantitative performance at high frame rates on the TNAD dataset.